Using high-speed imaging, the researchers showed that when our mouths open to produce speech sounds, a film of lubricating saliva initially spreads across the lips. As the lips part, the liquid film then breaks into filaments. Outward airflow from the lungs stretches and thins the filaments until they eventually rupture and disperse into the air as miniscule droplets — all within fractions of a second.
This droplet-producing mechanism is especially pronounced for so-called stop-consonants or “plosives” like “p” and “b,” which require the lips to firmly press together when forming the vocalized sound. Other sounds known as denti-alveolar plosives, such as “t” and “d” which involve the tongue touching the upper teeth and the jaw ridge just behind the teeth, likewise produce droplets at a much greater rate than when forming vowel sounds.

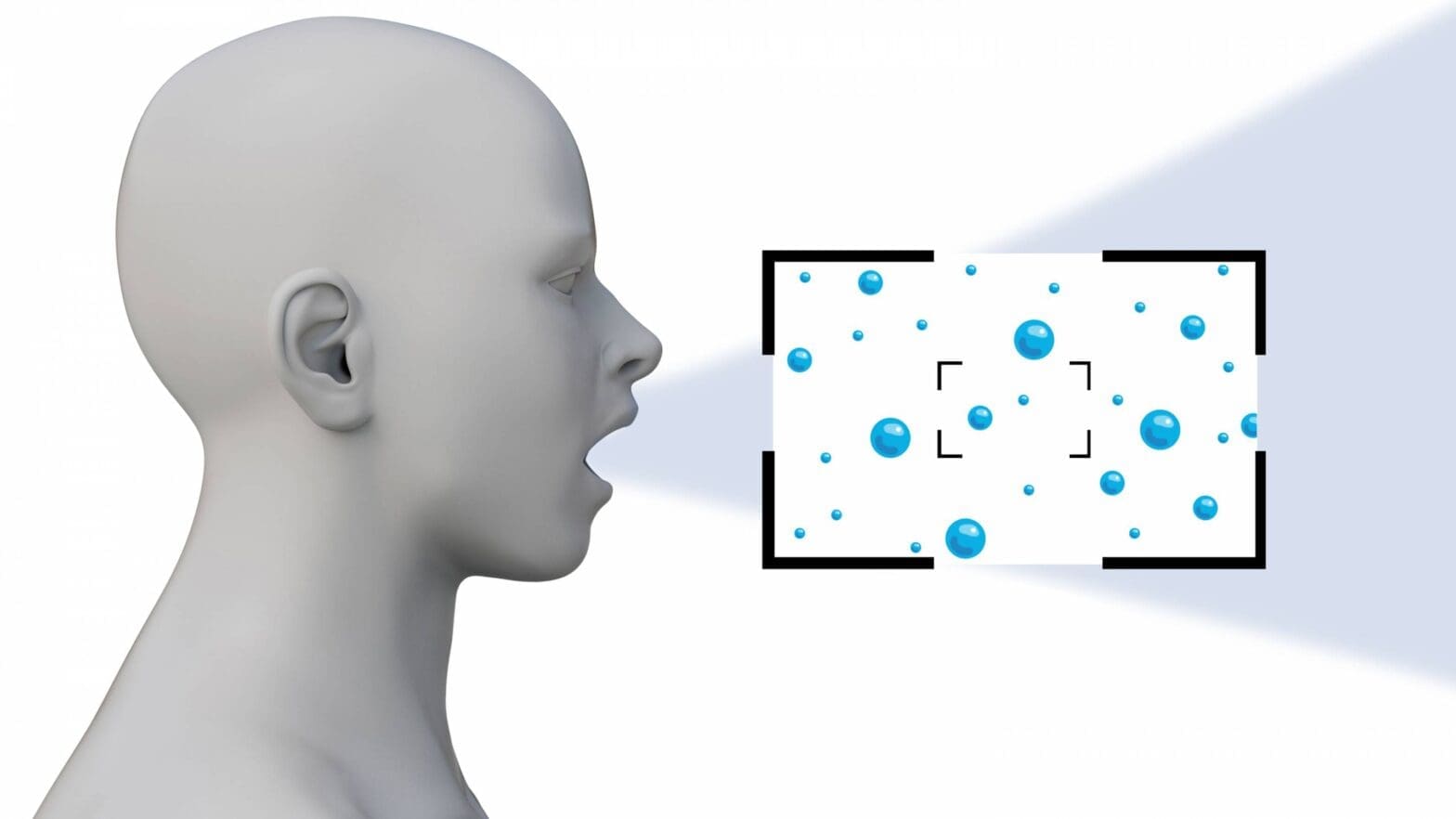
The researchers used this laser sheet to illuminate the saliva droplets. The laser light, originating at the left, is expanded to form a “sheet” going from left to right and about a meter high. The research subject (usually Manouk Abkarian of CNRS) would stand in front of the sheet or next to it, depending on the experiment. Drops from their speech or breath that crossed the sheet would produce flashes that they photographed and counted. Some experiments added a Halloween fog machine to see how the subject’s breath or speech droplets interact with the movement of ambient fog droplets.
A deeper understanding of this droplet formation and dispersal process should lead to new and better mitigation strategies, helping to slow down the current coronavirus pandemic along with future outbreaks.
“We have made the first direct visualization of the mechanism that produces droplets in the oral cavity during everyday speech,” said Howard Stone, the Donald R. Dixon ’69 and Elizabeth W. Dixon Professor of Mechanical and Aerospace Engineering. “Our study provides insights into the origin of droplets when people talk, which can aid in curbing the spread of diseases like COVID-19.”
The study appeared Oct. 2 in the journal Physical Review Fluids. Stone coauthored the study with Manouk Abkarian, a research director at the French National Centre for Scientific Research in the Centre de Biologie Structurale of Montpellier. Abkarian had come to Princeton on a planned, short sabbatical in the beginning of March 2020, coincidentally just before the University (and much of the rest of the world) went into a pandemic lockdown.
In those early weeks as COVID-19 infection rates soared, researchers from a wide range of disciplines began focusing on how the virus was transmitted. Likewise concerned, Stone and Abkarian wanted to bring their expertise in fluid mechanics to bear on the problem. The researchers zeroed in on asymptomatic transmission; that is, by people who were not coughing and sneezing and explosively emitting pathogen-laden, airborne particles.
“We wrote a grant proposal in April to investigate the fluid mechanics involved in asymptomatic transmission through the role of speech, when people who aren’t apparently sick are just normally interacting and talking,” said Stone.
To pursue the study, Stone and Abkarian received permission from the University, including the Institutional Review Board, to access his campus lab to pursue this urgent work while observing a strict social distancing protocol. There, Abkarian performed most of the experiments on himself, with some additional imaging of Stone speaking. The experimental setup involved Abkarian sitting in a chair in a room filled with mist from a fog machine. He vocalized various phonetics while speaking toward a laser sheet, which is a flat and thin plane of laser light. The laser sheet revealed any particles leaving Abkarian’s mouth due to the light-scattering effect they cause when crossing the sheet. A high-speed camera captured this scattering, enabling the researchers to gauge the level of droplet production per spoken sound.
To visualize the formation of the droplets during speech, the same camera zoomed in on the speaker’s mouth. The camera recorded at an extremely detail-revealing 5,000 frames per second under strong illumination. The millisecond-level, frame-by-frame perspective showed the deposition of a microscopic, lubricating, salivary layer on the lips as the lips press together prior to issuing a plosive consonant. The liquid layer draws into a vertical thin film as the lips separate. The film becomes unstable within a millisecond as it expands to about a millimeter in width. The film splits into numerous filaments that thin and quickly extend over centimeters in length to break finally into drops blown outward by air leaving the speaker’s mouth.
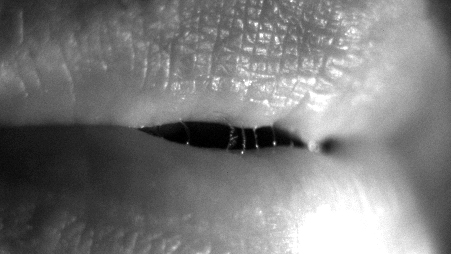
Researchers used high-speed cameras to analyze how speech produces small droplets.
Photo by the researchers
This caught-on-camera evidence contrasts with previous, mostly unsupported hypotheses regarding the formation of aerosolized droplets. Droplet formation has been presumed to occur in two ways: from thin films bursting deep in the lungs, or from airflow shearing droplets off of saliva-coated surfaces in the upper airway, which includes the throat and mouth. The jury remains out on whether those other proposed mechanisms play a role beyond the mechanism documented by Stone and Abkarian.
“No one has been able to obtain direct measurements or visualizations of droplet formation in the lungs or upper airway before,” said Abkarian. “Now with our study, there is compelling evidence that the stretching and breakup of saliva filaments during speech is behind aerosol formation.”
Wearing masks, as is near-universally recommended by public health experts and mandated in many jurisdictions, should effectively contain a significant portion of expelled aerosols, the researchers pointed out. Stone and Abkarian further suggested that the simple intervention of wearing lip balm should cut down on droplet formation during speaking.
When pandemic conditions allow, Stone and Abkarian would like to extend the imaging in their study to more participants to confirm that the droplet generation mechanism they documented is a general characteristic of human speech.
The researchers also are interested in differences between languages in terms of the variety and frequency of sounds their articulation invokes. It is possible that speakers of certain languages with many hard consonants, for instance, will tend to produce more droplets than speakers of languages featuring greater use of softer vowel sounds. People who do produce more spittle when they speak — dubbed “superemitters” — may not necessarily be superspreaders of COVID-19 or other saliva-borne diseases, however. That is because the infectiousness of any given droplet is likely based on the amount of virus it contains, and a person infected with COVID-19 who just happens to produce copious droplets may not also have a high viral load in their saliva or respiratory tract.
“We’re still learning an awful lot about how COVID-19 is transmitted,” said Stone. “Our hope is that this study will help in the overall fight against this devastating pandemic.”
The work was supported by the U.S. National Science Foundation and by the French National Centre for Scientific Research via a travel grant.