Her team also creates tools to identify and mitigate biases in AI systems, and promote fairness and transparency.
Russakovsky, an assistant professor of computer science, is a cofounder of AI4ALL, a national nonprofit that aims to bring young people from underrepresented groups into AI research. Since 2018, she has co-directed an AI4ALL camp for rising 11th graders at Princeton. In the 2021 virtual program, 24 students from around the country spent three weeks learning programming and AI basics, and applying their skills in group projects with guidance from Princeton graduate student instructors.
One group of participants explored the use of computer vision to process data from motion-activated cameras that scientists use to monitor wildlife. Another team developed algorithms to detect misinformation related to COVID-19, while a third group focused on systems that enable robots to predict human motion. Participants examined issues of privacy, security, and ethics, including how the choice of data used to train AI algorithms can introduce unintended biases.
Beyond its summer programs, hosted by 15 universities throughout North America, AI4ALL provides resources and mentorship for its alumni to continue their learning, launch independent projects, and pursue careers in AI.
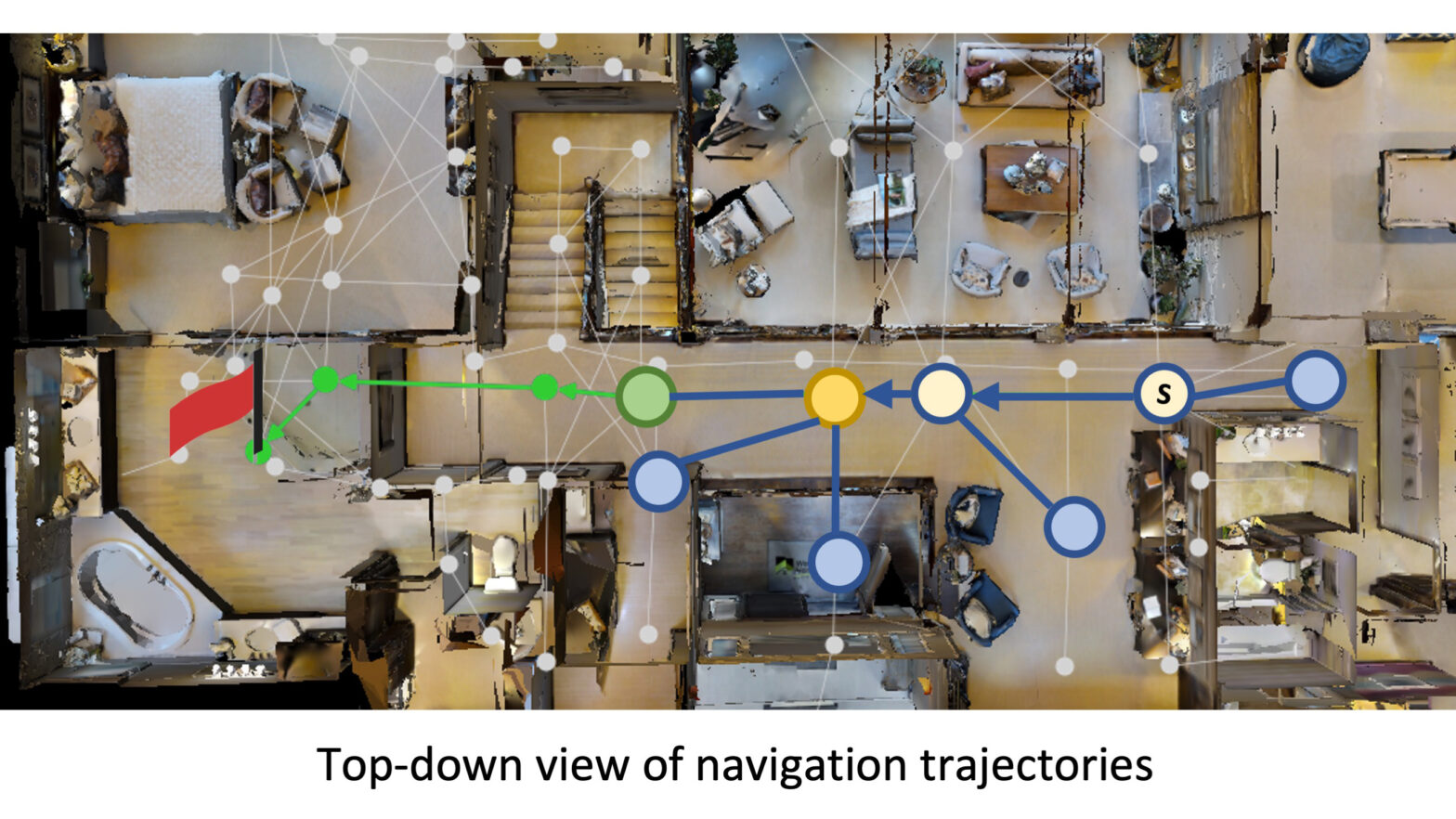
A current project in Russakovsky’s lab addresses how a robot can navigate an unfamiliar space by following a human’s instructions. This complex task requires robust systems for processing natural human language, as well as abilities to map the environment, plan movements, and course-correct when needed.
The lab recently made progress toward a single, adaptable computational model that combines all these features. At each step of navigation, the model’s algorithms direct the robot to efficiently explore many possible actions, and the robot continues to update the map of its environment and its past actions, which improves error correction.
The researchers tested their method on a benchmark simulation for natural language navigation that includes 22,000 sets of instructions directing a robot to move from one room of a building to another. The model allowed the robot to successfully follow instructions more than 50% of the time, outperforming previous methods.
“Even humans sometimes fail to find a location in a new building or campus,” said Zhiwei Deng, a postdoctoral research associate who coauthored the work with Russakovsky and Karthik Narasimhan, an assistant professor of computer science. “Errors can come from the new appearance of the room that the robot has never seen during training, and ambiguity on the language side when performing grounding to visual inputs. This problem requires the model to gradually accumulate information along with the navigation, perform error corrections when realizing a deviation from the instructions, and redo the planning based on current information.”