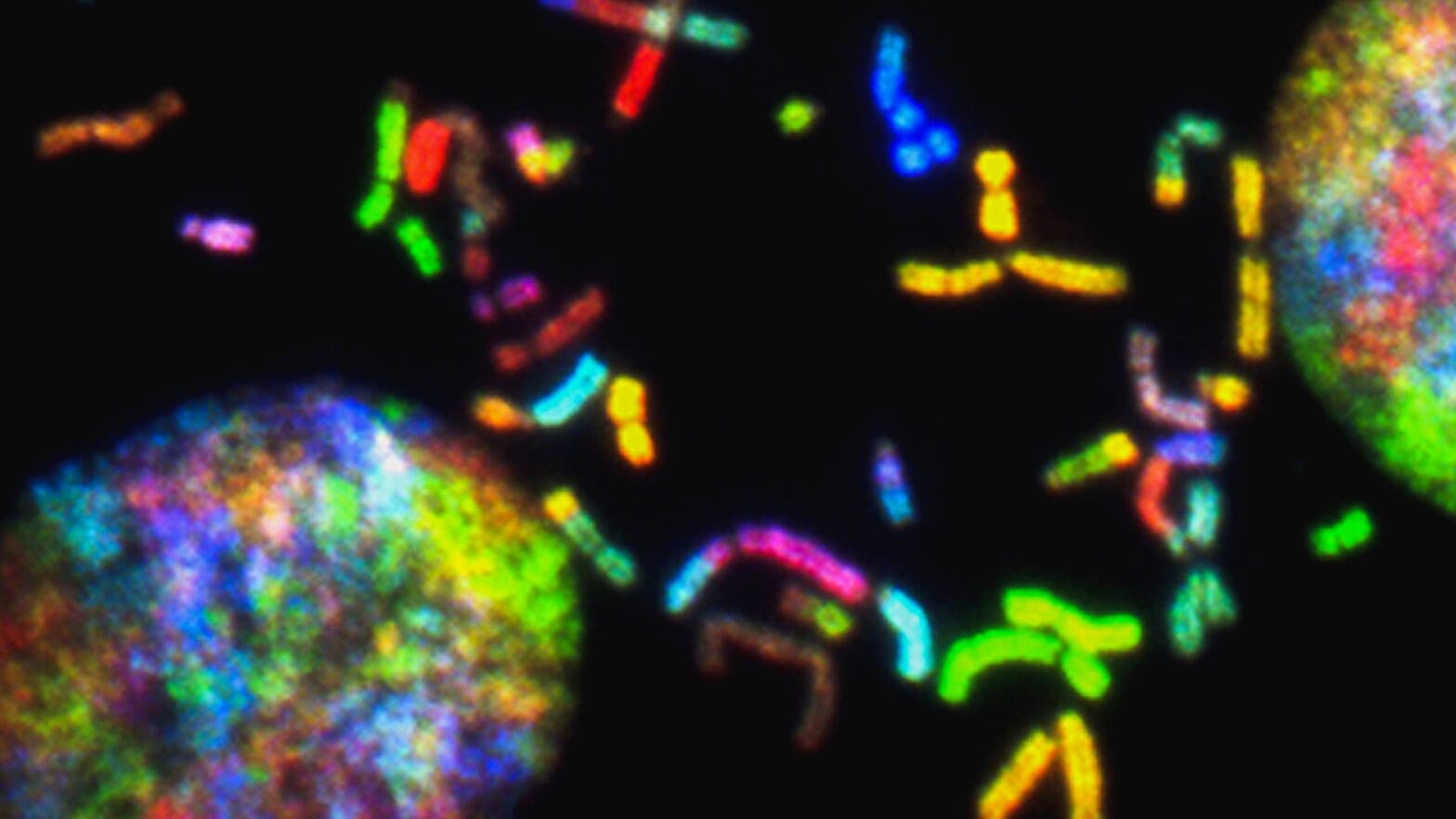
Now, methods developed by Princeton computer scientists will allow researchers to more accurately identify these mutations in cancerous tissue, yielding a clearer picture of the evolution and spread of tumors than was previously possible.
Losses or duplications in chromosomes are known to occur in most solid tumors, such as ovarian, pancreatic, breast and prostate tumors. As cells grow and divide, slip-ups in the processes of copying and separating DNA can also lead to the deletion or duplication of individual genes on chromosomes, or the duplication of a cell’s entire genome — all 23 pairs of human chromosomes. These changes can activate cancer-promoting genes or inactivate genes that suppress cancerous growth.
“They’re important driver events in cancer in their own right, and they interact with other types of mutations in cancer,” said Ben Raphael, a professor of computer science who co-authored the studies with Simone Zaccaria, a former postdoctoral research associate at Princeton.
Although medical science has recognized the mutations as critical parts of cancer development, identifying these losses or duplications in chromosomes is difficult with current technology. That is because DNA sequencing technologies cannot read whole chromosomes from end to end. Instead, the technologies allow researchers to sequence snippets of the chromosome, from which they assemble a picture of the entire strand. The weakness of this method is that it cannot easily identify gaps in the DNA strand or areas of duplication.
To address this problem, Raphael and Zaccaria created new mathematical tools that allow scientists to search the vast collection of DNA snippets and uncover whether there are either missing pieces or duplicates. The algorithms, dubbed HATCHet and CHISEL, are described in detail in separate publications on Sept. 2 in Nature Communications and Nature Biotechnology.
“All the cells you are sequencing come from the same evolutionary process, so you can put the sequences together in a way that leverages this shared information,” said Zaccaria, who will soon begin positions as a principal research fellow at the University College London Cancer Institute and a visiting research scientist at London’s Francis Crick Institute.
“The reality is that the technology for sequencing DNA in individual cells has limitations, and algorithms help researchers overcome these limitations,” said Raphael. “Ideally, both the sequencing technologies and the algorithms will continue to improve in tandem.”
Raphael’s research group has multiple collaborations with cancer researchers who are beginning to apply the HATCHet and CHISEL algorithms to sequences from various types of patient samples and experimental models.
The work was supported by the U.S. National Institutes of Health, the National Science Foundation, and the Chan Zuckerberg Initiative; as well as the O’Brien Family Fund for Health Research and the Wilke Family Fund for Innovation, both awarded by the Princeton School of Engineering and Applied Science